请求/响应模型和RTT
Redis的TCP的服务采用Client/Server模型。意味着一次查询将遵循以下步骤:
- 客户端发起请求阻塞直到服务器响应。
- 服务器会处理请求操作的命令,并返回结果。
例如下面的四次的命令执行
1 | 127.0.0.1:6379> incr x |
客户端和服务端的通讯是建立在网络之上,如果是回环链路(本地网络)将是非常快的,相反互联网之上将相对较慢。但是无论在哪种网络下,数据包从客服端到服务端,再由服务端返回到客户端并接收的一个周期我们叫做RTT(Round Trip Time),这样我们可以参考RTT时间来优化性能(比如插入大量的元素,或者添加大量的数据库键值)在回环链路的RTT是非常短的(ping 127.0.0.1 可以看到结果),但是我们写入大量数据时,性能依旧是个问题。
Redis 管道
Redis 管道的就是将多次需要执行的指令合并成一次传输,服务端会一次返回每个指令的结果。如:
1 | (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 |
回到上面的例子,使用管道进行发送
1 | (printf "incr x\r\nincr x\r\nincr x\r\n"; sleep 1) | redis-cli --pipe |
特别注意: 如果客户端通过管道发送大量的命令,服务端将会使用内存队列缓存每个命令结果。所以在发送时需要控制命令的数量。
不只是RTT的问题
使用管道是可以上少网络请求,从而减少RTT耗时。实际上除了网络层上面的时间消耗,使用非管道进行操作时,redis需要频繁的进行Socket I/O的read()和write() 频繁的上下文切换,是一笔巨大的开销。如果使用了管道,只需要一次的read(),,同理write()也只需一次系统调用,极大的减少了开销。这样每秒执行的总查询数,从最初几乎呈线性增加,最终达到不使用管道方法基准的10倍,
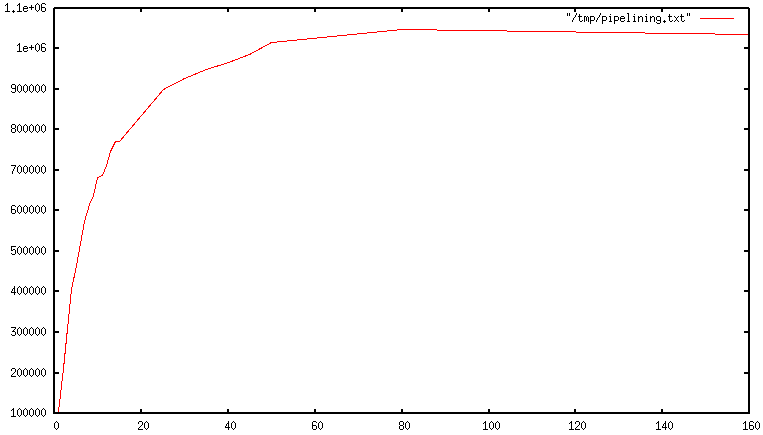
但是实际测试中却达到了惊人的400倍?基于Go语言的测试代码:
1 | // Redis server版本为5.0.4 On Mac OS X |
1 | with pipelining: 20.74797ms |
管道和脚本对比
Redis在2.6之后的版本中支持脚本。管道的一些例子可以直接转换到脚本方式更高的效率执行。特别是需要在服务端进行大量计算时,脚本可以最小延迟的执行,使得读取,计算,写入等操作变的非常快。
扩展:为什么在本地回环链路上循环执行操作还是很慢?
1 | # 伪代码 |
这段代码不停的进行SET操作,本地回环链路中,都是在同一台机子测试时,只有内存的数据拷贝,实际上应该是不会有额外的损耗的?但是却却相反,依然很慢。这是为什么呢?真实原因是系统不是一直都运行某个程序的,任何程序都是在系统的内核调度下运行,所以频繁SET系统要进行频繁的调度才能最终完成任务,本质上还是操作太多的IO操作,才导致性能下降。这就是为什么本地环境下测试依然很慢的原因。